

上周二,Meta宣布推出全新的开源AI语言模型系列Llama 2,其显著之处在于其商业许可证,这意味着这些模型可以集成到商业产品中,而不同于其前身。这些模型的规模从7亿到700亿个参数不等,并据Meta称,“在我们测试的大多数基准测试中,它们的性能超过了开源聊天模型。”
“这将改变LLM市场的格局,”首席AI科学家Yann LeCun在推特上发文表示。“Llama-v2现已在Microsoft Azure上可用,并将在AWS、Hugging Face和其他供应商上提供。”
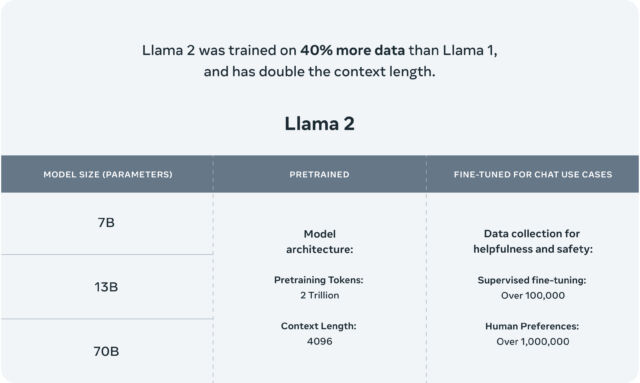
据Meta称,其Llama 2“预训练”模型(即基本模型)是基于2万亿个标记进行训练的,其上下文窗口为4,096个标记(单词片段)。上下文窗口决定了模型一次可以处理的内容长度。Meta还表示,为了类似ChatGPT的聊天应用,Llama 2还进行了“超过100万个人类标注”的微调。
虽然Llama 2在性能上无法与OpenAI的GPT-4相媲美,但对于一个开源模型来说,它表现不错。根据Nvidia的高级AI科学家Jim Fan的说法,“70B在推理任务上接近GPT-3.5,但在编码基准测试上存在明显差距。它在大多数基准测试中与或优于PaLM-540B,但仍远远落后于GPT-4和PaLM-2-L。”有关Llama 2的性能、基准测试和构建的更多详细信息可以在Meta于上周二发布的一篇研究论文中找到。
今年2月,Meta发布了Llama 2的前身LLaMA,并以非商业许可的形式开源。虽然官方上只允许拥有特定资格的学术界人士使用,但很快有人将LLaMA的权重(包含训练的神经网络参数值的文件)泄露到了种子站点上,并在AI社区广泛传播。很快,LLaMA的微调版本,如Alpaca,迅速涌现,为一个迅速发展的地下LLM(大型语言模型)开发场景提供了种子。
Llama 2将这一活动更加公开化,因为它允许商业使用,不过潜在的许可证持有者如果“上一个日历月活跃用户数超过7亿”,必须向Meta请求特殊许可,这可能阻止像亚马逊或谷歌这样规模的巨头免费使用它。
开源AI模型的力量与危险
尽管开源AI模型在爱好者和寻找无审查聊天机器人的人中非常受欢迎,但它们也引起了争议。Meta在支持主要的开源基础模型方面是独一无二的,而那些采用闭源技术的公司包括OpenAI、微软和谷歌。
批评者指出,开源AI模型存在潜在风险,比如在合成生物学领域或生成垃圾邮件或虚假信息方面被滥用。可以想象,Llama 2可能被用于这些用途,尽管这些用途违反了Meta的服务条款。目前,如果有人在OpenAI的ChatGPT API上进行受限行为,他们的访问权限可能会被吊销。但对于开源软件来说,一旦权重被发布,就无法收回。
然而,支持开源AI的人通常认为,开源AI模型鼓励透明度(在训练数据方面),促进经济竞争(不将技术限制在巨型公司手中),鼓励言论自由(无审查),并使AI的使用普及化(没有付费限制)。
或许是为了预防可能的批评,Meta还发布了一份简短的《支持Meta开放式AI方法的声明》,其中写道:“我们支持开放式创新的AI方法。负责任和开放式创新让我们所有人都有参与AI开发过程的利益,并为这些技术带来了可见性、审查和信任。开放今天的Llama模型将使每个人都能从这项技术中受益。”
截至周二下午,这份声明已经得到一些高管和教育工作者的签署,包括Drew Houston(Dropbox的CEO)、Matt Bornstein(Andreessen Horowitz的合伙人)、Julien Chaumond(Hugging Face的CTO)、Lex Fridman(MIT的研究科学家)和Paul Graham(Y Combinator的创始合伙人)。
尽管Llama 2是开源的,但Meta并未披露创建Llama 2模型所使用的训练数据来源,Mozilla值得信赖的AI资深研究员Abeba Birhane在Twitter上指出了这一点。缺乏训练数据透明度仍然是一些LLM批评者的症结所在,因为教导这些LLM“知识”的训练数据通常来自对互联网的未经授权抓取,对隐私或商业影响关注较少。在Llama 2的研究论文中,Meta表示“已经努力删除某些已知含有大量私人个人信息的网站的数据”,但未列出这些网站是哪些。
目前,任何人都可以通过在Meta的网站上填写表单来请求下载Llama 2。《Ars Technica》提交了下载请求,大约一个小时后收到了下载链接,这可能意味着列表可能需要手动筛选。