

在数字产品设计中,概念构思是一个关键阶段,想法开始成形。这不仅仅是勾勒初步设计的过程;它涉及到想象产品的功能、用户体验和审美吸引力。在这个阶段创建的资产至关重要。它们不仅有助于阐明想法,还在将概念嵌入更具体的东西方面起着关键作用。这有助于唤起你最终希望产品体验给最终用户带来的情感,并且对于客户的测试和批准也非常有用。
根据我的经验,设计师通常在互联网上寻找与他们设想的东西大致相符的素材,然后在设计的后期创建相应的图像。这只是一个近似值,通常是不合适的插图的混合体,而且还会花费相当多的时间。
在过去的一年里,我尝试将基于AI的渲染集成到我的工作流中。这不仅加速了创建和迭代这些图像的过程,而且也使得没有太深3D专业知识的设计师更容易使用。今天与大家分享的就是这种新的工作流。
传统 3D 渲染的美丽与挑战

Bureau Benjamin 在 Redshift 中创建的华丽渲染,突出了人们可以从使用传统渲染技术精心制作的图像中获得的质量。这些图像有时与现实难以区分。
传统的3D工作流程是高保真视觉创作的基石。创建这些图像的过程大致分为三个阶段,每个阶段都需要对细节进行细致入微的关注,对工具和艺术过程都有深刻的理解,需要多年的经验来掌握。
- 建模:在这个阶段,为场景制作3D模型。对于经验较少的艺术家来说,这个过程可能相当具有破坏性,如果犯了错误,就需要重新开始。对于这一步骤,对你选择的3D软件的专用工具的完全了解是必要的。
- 贴图和照明:这个阶段涉及向模型添加颜色、纹理和光照,对于场景的真实感和情感设置至关重要。根据我们对场景的方向,这一步骤可以相当简单,也可以极其复杂。
- 渲染:最后,像Octane和Blender的Cycles这样的渲染器被用于其真实的光物理学,使得可以在创建从逼真到抽象的视觉效果时获得高度的细节和灵活性。对于具有动画的复杂场景,这一步可能需要几小时才能生成几秒的镜头。

使用 Cinema4D 和 Octane 制作的最小渲染效果
无偏差渲染器如Octane和Blender的Cycles,正如其名称所示,模拟光照和材质时较少使用偏见,意味着它们在模拟过程中不采用捷径。它们基本上用虚拟的光子覆盖场景,随着它们在场景中弹跳,收集有关场景的信息,最终投射到虚拟相机的视野中。
这导致了图像具有卓越的质量和逼真度,但需要大量的计算能力和时间,使其成为一种资源密集型的选择。这也意味着强大的GPU是必要的,而这对于只是对探索创建这些图像感兴趣的人来说并不总是经济实惠的选择。这些工具在复制光的真实世界物理方面表现出色,提供了无与伦比的细节和逼真度。它们具有灵活性,可以创建从照片般逼真的场景到超现实、抽象的视觉效果,使其成为3D艺术家工具库中不可或缺的一部分。
在 Blender 中创建简单抽象形状的短延时
并不是每个人都知道如何使用这些复杂的渲染工具。实际上,很少有人知道。我一直在业余时间学习和实践3D超过3年,但甚至还没有开始深入了解Blender的潜力。
打造一幅优雅的图像不仅需要对强大的工具具有很强的控制和技术实力,还需要对艺术和设计原理有深刻的理解。这可能让人感到不知所措和灰心丧气。除此之外,这种详细和受控的方法并不适用于在项目的早期阶段进行快速概念构思和迭代,尤其是在短短几天内需要提出各种方向和创意的情况下。
当你试图在短短几天内提出各种方向和创意时,花费4小时来创建和渲染一张图像可能会非常具有挑战性。
人工智能生成图像的潜力和局限性

使用SD,像“东京的最小工作室公寓”这样简单的提示就可以提供惊人的结果。将提示切换为“充满植物的最小公寓”会给您一种完全不同的感觉,毫不费力。
另一方面,由AI生成的图像引入了近乎无限的视觉可能性的领域,促使快速迭代,其中微小的提示调整可能导致完全不同的创意方向。与AI生成的图像相比,迭代起来的便捷性是无与伦比的 — 即使是在提示中稍微调整,也可能导致视觉风格的显著变化。
然而,这种方法存在一个主要问题:缺乏控制。如果我们试图创建一张与引言中相似的图像,具有特定的内部风格、构图和设置,那么我们可能就像在玩彩票一样。
使用 Midjourney V6 生成的图像
反复生成图像,直到找到符合你心中风格、构图、光照和布局的平衡的图像,这并不是一种可持续的方法。这个过程可能非常缓慢且令人沮丧,特别是在试图匹配图像与特定产品和品牌的审美要求时。
关键在于掌控。真正的挑战在于充分利用AI的速度和细节,同时对创意输出保持明确的掌控。
AI 增强 3D:创造力和控制力

借助AI渲染,一个用最小努力创建的简单场景可以立即变成一个复杂的渲染。在这里,我尝试重新用不同的风格从零开始用3D重新创造本杰明的客厅。
将开源AI工具集成到Blender等工具中,如ControlNet,标志着解决上述一些挑战的第一步。ControlNet可以读取场景中的信息,例如:
- 深度:任何给定对象距离摄像机和其他对象有多远。
- 线条:场景中物体的边缘在哪里?
- 语义:识别场景中的物体是什么(例如,这是一张沙发;这是一盏灯)。

ControlNet 集成在 Blender 内部,使用节点系统来选择将哪些信息输入到扩散模型中。这里,图像是使用深度与提示相结合生成的

在这里,可以连续看到原始 3D 场景、语义图、深度图以及一些通过切换提示创建的生成图像
这种新的工作流使设计师在保留对其工作的控制的同时,又能从AI提供的灵活性中受益。设计师可以从一个简单的3D模型开始,利用AI迅速探索不同的视觉方向并进行快速调整。这种方法产生了一个协同的过程,其中传统3D建模的精度与AI的适应性和速度相结合:
- 建模:创建简单的3D模型(尽管生成3D技术的进步已经简化了这一步骤),更注重比例、布局和构图,而不是细节。
- 生成:ControlNet与扩散模型共享场景信息,扩散模型生成一张保持构图和主题完整的图像。(如果你见过定制的QR码,它们使用ControlNet来实现这一点)
- 迭代:调整对生成图像的控制。如果控制很大,AI会确保渲染图像与模型的比例相匹配,但限制细节和“创造性”。

以基本的3D场景开始的一个关键优势是可以自由地探索它,就像操作相机一样,轻松调整透视、构图和焦距。在这里,我们将镜头拉近到场景中央的灯。

可以看到之前和之后的情况,首先是深度图,其次是生成的图像。注意灯上的大理石花纹、桌子上的倒影以及桌子上的细节。

风格差异但构图/比例一致的示例,可以通过更改提示但使用相同的 3D 输入来实现。

有趣的是,当两个相同的对象并排放置时,模型会理解它并一致地生成它们。
这种AI增强的工作流程的一个关键优势是能够更有效地与创意团队和产品设计师分享早期概念。在流程的早期展示AI增强的视觉效果有助于为项目确定具体的方向,促进更好的沟通,节省宝贵的时间和资源。

使用此方法渲染的其他对象的示例
这种方法还支持创建一致的情绪板,这在整个设计过程中充当着重要的参考点。这些情绪板可以迅速调整和完善,使我们设计师能够创造一个贯穿项目艺术方向的一致的视觉语言。
新的工具也在不断涌现,这使得这种工作流程变得更加强大。比如,由LCM-LoRA(潜在一致性模型 — 潜在残差适配器)驱动的Krea是扩散模型领域的一个创新,它提供了接近实时的渲染,几乎可以立即响应您的输入。

使用 Krea 进行即时渲染,同时在 Blender 中捕获场景作为输入

经过一些调整和放大后,可以通过此过程生成高质量的图像
引导混乱:定制训练模型

一组最小的 3D 资源,用于训练自定义稳定扩散模型,以创建具有干净背景和有趣材质的一致渲染
在这篇文章中,设计中使用AI的主要焦点主要集中在其速度和协同创作的能力上。然而,由于大多数模型都被设计为通用模型,一个常见的挑战是需要复杂的提示工程来捕捉特定的风格。
如果我们的目标是为我们具有特定愿景的产品使用这些图像,我们很快就会发现自己重新回到了生成式抽奖的状态,一遍又一遍地生成图像并调整提示,直到找到适合我们项目的东西。
幸运的是,扩散模型可以被训练成特定风格或艺术方向的专家。通过整理灵感来源,我们可以使用Dreambooth等工具对模型进行训练,使其输出更加一致,同时保持我们努力维持的创意控制。

基于简单的字母进行的快速探索。这组图像感觉一致,唯一的提示输入是澄清我想要它生成的材料。其余的图像由自定义模型决定。有趣的是注意到生成的图像似乎遵循材料的物理约束。
AI在设计的早期阶段,如内部概念开发和头脑风暴中具有最大的益处。如果经过正确训练,模型和由AI生成的视觉效果可以作为团队内创意讨论的基础,为灵感和初步构思提供广泛的可能性。

从非常简单的形状到更抽象和无定形的形状的探索
在我看来,将AI纳入设计工作流的目标并不是替代艺术家的需求,而是增强和加速在预算分配给艺术家贡献之前的概念阶段。这种方法类似于每位设计师目前所做的:在最初的概念阶段在线收集与一般风格相匹配的图像,然后过渡到经过许可的资产或定制创建的艺术品。
这是关于将AI作为一个工具,以补充人类创造力,帮助快速探索初步的想法和方向,同时认识到专业艺术在实现最终设计愿景方面的价值。

在3D设计工作流中使用AI生成快速插图和图像只是冰山一角。创新发生得飞快。我毫不怀疑,AI是渲染的未来,AI渲染将原生支持3D软件以及游戏引擎。事实上,AI已经被用于在Blender中去噪和提高渲染的分辨率,同时在最新的Pixar’s Elements中优化渲染时间,在Unreal Engine中优化帧率。
对于这些工作流更广泛地被采用来说,对风格和构图的掌控仍然是主要的障碍。除此之外,学习如何使用Stable Diffusion等工具仍然是一项相当混乱和技术性的工作。扩散模型背后的技术对于那些没有神经网络和计算机科学学位的人来说仍然是一个神秘。此外,用户必须与之交互的界面令人沮丧,主要是因为开发者构建它们的速度非常快,有很大的改进空间。
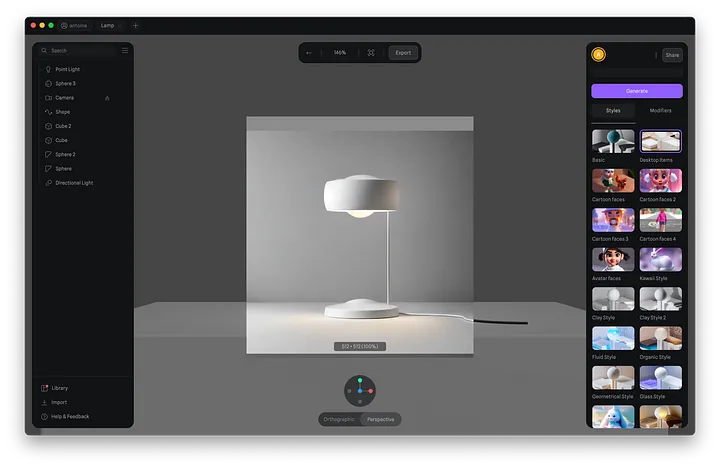
像Spline这样的工具正处于使3D和AI渲染更多样化的设计师更加可访问的前沿。最近,他们推出了他们对AI渲染的看法,“Style Transfers”使用了与我们今天讨论的类似的技术。通过简化这些复杂的过程,他们正在使创造高质量视觉效果的能力变得平民化,为设计师打开新的可能性,而不管他们的技术水平如何。
展望未来,这个不断发展的领域的下一个重要前沿是视频生成和生成式3D。像Runway这样的初创公司,以及开源工具如Stability的Vido Diffusion模型或AnimateDiff正在迅速改进,让用户能够对他们生成的图像进行动画处理。

到目前为止,从静止画面中获得的运动仍然受到限制,但视频到视频的输出将变得越来越好,使我们能够看到充分发挥AI渲染在产品动画中的潜力。