

由人工智能模型生成的视频,其幕后制作过程会是什么样?你可能会联想到定格动画——需要逐帧制作并拼接大量图像,但对于OpenAI的SORA和谷歌的VEO 2这类”扩散模型”而言,情况并非如此。
这些系统并非逐帧(或称”自回归式”)生成视频,而是同时处理整个序列。虽然生成的片段常具照片级真实感,但过程缓慢且无法实时修改。
来自MIT计算机科学与人工智能实验室(CSAIL)和Adobe Research的科学家们开发出一种名为”CausVid”的混合技术,可在数秒内生成视频。如同敏锐的学生向博学的导师学习,这套系统通过全序列扩散模型训练自回归系统,使其能快速预测下一帧,同时确保高质量与连贯性。CausVid的学生模型仅需简单文本提示即可生成片段——将静态图转为动态场景、延长视频时长,或在生成过程中根据新指令实时调整内容。
这项动态工具将原本需要50步的流程简化为几个步骤,支持快速交互式创作。它能呈现众多富有想象力的艺术场景:纸飞机蜕变为天鹅、猛犸象穿越雪原、孩童踩水洼嬉戏。用户还可通过追加指令动态扩展内容,例如首先生成”男子过马路”场景,再补充”他到达对面人行道后开始写笔记”。

CausVid生成的视频展现了其流畅、高质量的创作能力。图片来源:研究团队
CSAIL研究人员表示,该模型可应用于多种视频编辑场景:通过生成与翻译音频同步的视频帮助观众理解外语直播;为电子游戏实时渲染新内容;快速制作训练模拟来教导机器人新技能。
刚毕业于电子工程与计算机科学专业的CSAIL成员田伟寅(Tianwei Yin SM ’25, Ph.D. ’25)指出,模型优势源于其混合架构:”CausVid融合了预训练扩散模型与文本生成模型中常见的自回归结构。这个AI教师模型能预判后续步骤,指导逐帧系统避免渲染错误。”
共同第一作者张强现为xAI研究科学家,曾任CSAIL访问研究员。团队还包括Adobe Research科学家Richard Zhang、Eli Shechtman、Xun Huang,以及MIT教授Bill Freeman与Frédo Durand两位CSAIL首席研究员。
因果(视频)链效应
传统自回归模型生成的视频往往初看流畅,但后续质量逐渐下滑。例如人物跑步场景可能起始逼真,随后腿部却出现不自然摆动,暴露出帧间不一致(即”误差累积”问题)。
早期因果方法需自主逐帧预测,易产生误差。CausVid则通过高性能扩散模型向简易系统传授通用视频知识,使其既能快速生成,又能保持画面流畅。
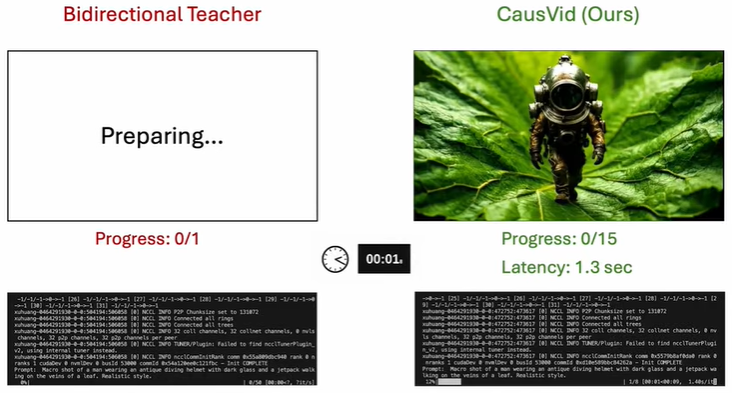
在生成10秒高清视频的测试中,CausVid表现超越OpenSORA、MovieGen等基线模型,速度提升达百倍的同时产出最稳定、优质的片段。在30秒视频测试中,其质量与连贯性同样领先同类,预示其未来或可制作数小时甚至无限时长的稳定视频。
后续研究发现,用户更青睐CausVid学生模型生成的视频。”自回归模型的速度优势显著,”田伟寅表示,”其视频质量与教师模型相当但耗时更少,代价是视觉多样性稍逊。”
在900余条文本到视频指令测试中,CausVid以84.27分位居榜首,在成像质量、人物动作真实性等指标上超越Vchitect、Gen-3等顶尖视频生成模型。
尽管已是AI视频生成的高效突破,研究团队认为通过精简因果架构和领域专用数据集训练,未来或可实现即时生成,特别在机器人与游戏领域产出更优质内容。
卡内基梅隆大学助理教授Jun-Yan Zhu(未参与本研究)评价:”当前扩散模型速度远慢于大语言模型或图像生成模型。这项研究改变了局面,使视频生成效率大幅提升,意味着更流畅的串流速度、更强的交互应用,以及更低的碳足迹。”